
Selenium może służyć nie tylko do automatyzacji, lecz także do web scrapingu. W tym artykule pokażę Ci jak robić web scraping w Selenium.
Poprzednio na blogu opisywałem zastosowanie Selenium w automatyzacji. Omówiłem w nim podstawowe użycie narzędzia. W tym artykule jednak opiszę wykorzystanie Selenium do web scrapingu.
Powinienem zacząć od tego, że Selenium nie jest przeznaczone typowo do web scrapingu, co może powodować pewne problemy.
Web scraping Selenium – wady
Największą wadą stosowania Selenium pod kątem web scrapingu jest jego „toporność”.
Ładowanie strony
Bardzo często podczas lokalizowania elementu pojawiają się problemy ze znalezieniem go. Większość z tych problemów wynika z faktu, że strona nie została jeszcze w pełni załadowana.
Rozwiązaniem tego są co prawda oczekiwania na załadowanie konkretnego elementu, jednak znacznie spowalnia to proces scrapowania.
Problemy z powtarzalnością
Innym problemem, który potrafi porządnie zirytować programistę Selenium jest brak 100% powtarzalności czynności wykonywanych za pomocą narzędzia.
Wyobraź sobie, że napisałeś skrypt, który działa na konkretnym typie strony, na przykład aukcji w sklepie internetowym. Uruchamiasz go wielokrotnie, jednak co jakiś czas otrzymujesz błąd na przykład mówiący o tym, że Selenium nie było w stanie kliknąć w konkretny przycisk ze względu na to, że inny element go zasłonił lub elementu po prostu nie znaleziono.
Nawet strony o identycznym schemacie różnią się od siebie, na przykład wysokością. Wynika to różnej długości treści, różnych rozmiarów obrazków czy nawet różnej liczby komentarzy.
Przez te różnice Selenium czasami nie jest w stanie wejść w interakcję z elementem. Często rozwiązaniem tego problemu jest przewinięcie (przescrolowanie) do niego, jednak nie jest to remedium na wszystkie tego typu problemy.
Niska wydajność
Selenium nie zostało zoptymalizowane pod kątem web scrapingu. Scrapując przy użyciu omawianego narzędzia korzystamy z rzeczywistej aplikacji przeglądarki, co jest znacznie mniej wydajne niż pobieranie treści strony korzystając jedynie z żądań protokołu HTTP.
Używanie przeglądarki powoduje również większe zużycie zasobów przy scrapowaniu.
Proxy
Wiele stron zabezpiecza się przed scrapowaniem blokując adresy IP, z których wychodzi dużo żądań, szczególnie takich, które nie kończą się wykonaniem kodu JavaScript. Dlatego scrapowanie bardzo często wiąże się z używaniem proxy.
I tutaj Selenium ma ogromny problem.
Selenium natywnie nie wspiera autoryzacji proxy polegającej na podaniu nazwy użytkownika i hasła.
Niestety, ta metoda uwierzytelnienia użytkownika jest stosowana w większości proxy. Alternatywną metodą jest umieszczenie adresu IP na tzw. whitelist, czyli liście adresów IP, które zostają uwierzytelnione automatycznie. Rozwiązanie to niestety nie zawsze działa.
Zalety scrapowania w Selenium
To, że w przypadku Selenium korzystamy z prawdziwej przeglądarki, może być równo wadą, jak i zaletą.
Symulacja zachowania użytkownika
Dzięki temu dużo łatwiej nam symulować zachowanie zwykłego użytkownika, gdyż przeglądarka ma od razu ustawiony odpowiedni user-agent, wykonuje kod JavaScript oraz poprawnie ładuje grafiki umieszczone na stronach.
Istnieją jednak inne rozwiązania pozwalające to osiągnąć, jak np Puppeteer czy Splash. Rozwiązania podobnie jak Selenium wykorzystją sterowniki przeglądarek (najczęściej Chrome), jednak są dużo „lżejsze”.
Integracja ze Scrapy
Selenium może być również zintegrowane ze Scrapy – najpopularniejszym frameworkiem do web scrapingu.
Wykorzystywane jest zamiennie ze Splashem w celu wykonania kodu JS na stronie.
Społeczność
Selenium to narzędzie używane już bardzo długo, które zdążyło doczekać się sporej społeczności.
Testerzy, web scraperzy, fani automatyzacji to grupy zainteresowania tym narzędziem, których aktywność w internecie (między innym na portalu stackoverflow) jest w stanie pomóc w razie problemów z narzędziem.
Kiedy używać Selenium do web scrapingu?
Ogólnie rzecz biorąc nie zalecam scrapowania w Selenium.
Jedynym wyjątkiem od tej reguły jest scrapowanie strony, której obsługę i tak automatyzujemy przy pomocy Selenium.
W takiej sytuacji oczywistym jest scrapowanie wykorzystując Selenium, aby nie musieć wielokrotnie łączyć się do konkretnego serwisu.
Web Scraping Selenium
Przejdźmy wreszcie do scrapingu 🙂
Co do podstaw narzędzia jeszcze raz odsyłam Cię do wpisu o automatyzacji w Selenium.
Oczywiście aby zacząć pobieranie należy utworzyć obiekt sterownika przeglądarki (webdriver) oraz wejść na daną stronę. Do tego posłuży nam metoda get.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://kamil.kwapisz.pl/")
Następnie możemy przejść do pobierania konkretnych danych ze strony
Metody pobierania danych
Scrapując w Selenium możemy wyróżnić dwie metody pobierania danych ze strony:
- Pobieranie danych bezpośrednio z elementów Selenium
- Przekazanie kodu strony do parsera HTML i pobieranie danych za jego pomocą
Przy scrapowaniu najważniejszym czynnikiem jest szybkość, dlatego sprawdźmy, która metoda jest najszybsza.
Zadaniem, na jakim to sprawdzimy, będzie pobranie wszystkich tytułów artykułów na stronie głównej bloga oraz ich dat publikacji.
Pobieranie danych z elementów Selenium
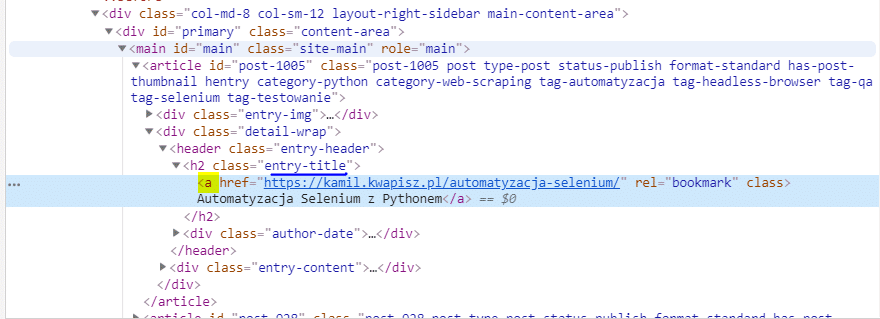
Korzystając z narzędzi deweloperskich Google Chrome możemy zauważyć, że tytuły kryją się w znaczniku <a>, który znajduje się w znaczniku <h2> o klasie „entry-title„. Wyszukamy więc elementy korzystając z prostego selektora CSS.
def parse_titles_from_driver(driver) -> list:
title_elements = driver.find_elements_by_css_selector(".entry-title a")
titles = [title.text for title in title_elements]
return titlesAby pobrać daty publikacji wystarczy skorzystać z wyszukiwania po klasie „posted-on„.
def parse_dates_from_driver(driver) -> list:
dates_elements = driver.find_elements_by_class_name("posted-on")
dates = [date.text for date in dates_elements]
return datesTeraz zepnijmy to wszystko w jedną metodę i zmierzmy czas jej trawania:
from time import perf_counter
def extract_data_with_selenium(driver):
t = perf_counter()
titles = parse_titles_from_driver(driver)
dates = parse_dates_from_driver(driver)
print(f"Czas trwania ekstrakcji Selenium: {perf_counter() - t}")Pobieranie danych za pomocą parsera
W tym scenariuszu z Selenium pobierzemy kod strony, który przekażemy do parsera. Wykorzystamy tutaj parser BeautifulSoup.
from bs4 import BeautifulSoup
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://kamil.kwapisz.pl/")
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")Parsując tytuły przy użyciu BeautifulSoup wyszukamy wszystkie znaczniki <a>, o atrybucie rel=”bookmark”:
def parse_titles_from_soup(soup) -> list:
title_elements = soup('a', {'rel': "bookmark"})
titles = [title.text for title in title_elements]
return titlesDaty wyszukamy ponownie za pomocą nazwy klasy:
def parse_dates_from_soup(soup) -> list:
date_elements = soup(span', _class="posted-on")
dates = [date.text for date in date_elements]
return datesPonownie złączmy to w jedną metodę:
def extract_data_with_soup(soup):
t = perf_counter()
titles = parse_titles_from_soup(soup)
dates = parse_dates_from_soup(soup)
print(f"Czas trwania ekstrakcji BeautifulSoup: {perf_counter() - t}")Porównanie szybkości metod
Pomiar czasu wykonania metod wykonałem po 1000 razy dla każdej z metod i wynik uśredniłem.
Rezultaty:
| metoda | średni czas wykonania metody |
| ekstracja przy użyciu Selenium | 0.19 s |
| ekstracja przy użyciu BeautifulSoup | 0.008 s |
Jak widać ekstracja danych przy użyciu BeautifulSoup okazała się ponad 23 razy szybsza.
Dla wyrównania szans postanowiłem zmodyfikować metodę do ekstrakcji danych z BeautifulSoup.
def extract_data_with_soup2(driver):
t = perf_counter()
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
titles = parse_titles_from_soup(soup)
dates = parse_dates_from_soup(soup)
return float(perf_counter() - t)Teraz metoda jako parametr otrzymuje obiekt drivera i za każdym razem pobiera ona kod strony i tworzy z niego obiekt BeautifulSoup. Stwórzmy również powyższej metody, która wykorzysta parser „lxml” zamiast „html.parser”.
Porównanie czasu wykonania wygląda teraz następująco:
| metoda | średni czas wykonania metody |
| ekstracja przy użyciu Selenium | 0.19 s |
| ekstracja przy użyciu BeautifulSoup | 0.008 s |
| ekstracja przy użyciu BeautifulSoup z obiektu driver (html.parser) | 0.075 s |
| ekstracja przy użyciu BeautifulSoup z obiektu driver (lxml) | 0.031 s |
Nawet jeżeli korzystamy za każdym razem z obiektu drivera to pobieranie danych z wykorzystaniemy BeautifulSoup jest 2.5 raza szybsze dla parsera html.parser i ponad 6 razy szybsze dla parsera lxml.
W przypadku tego porównania przewaga BeautifulSoup jest ogromna, jednak to tylko jeden konkretny przypadek, który nie jest wystarczający do wysnucia wniosku, jednak moim zdaniem jest dobrym punktem odniesienia 🙂
Jeżeli chcesz aby porównać metody ekstrakcji dokładniej to koniecznie daj znać 😉
Przejście na następną stronę
Zakładamy, że pobraliśmy już wszystkie potrzebne nam dane z jednej strony. Czas przejść na kolejną. W naszym przypadku będzie to po prostu kolejna strona z postami.
W tym momencie mamy dwa (a właściwie trzy) wyjścia.
Własna obsługa stronnicowania
Pierwszy sposób ma niewiele wspólnego z omawianym narzędziem. Praktycznie każda strona wykorzystująca stronnicowanie (paginację) pozwala na dostęp do określonej strony w kolejności za pomocą odpowiedniego adresu URL.
Można to zauważyć wchodząc na dalszą stronę wyników. W przypadku mojego bloga jest to URL https://kamil.kwapisz.pl/page/2/ . Podmieniając numer strony możemy dostać się do innych stron wyników.
Wadą powyższej metody jest to, że musimy samemu kontrolować czy na danej stronie są jeszcze wyniki, oraz czy istnieje następna strona.
Obsługa przycisków
Kolejną metodą jest skorzystanie z guzika, który przenosi nas na następną stronę. Skorzystajmy z narzędzi deweloperskich by dowiedzieć się o nim więcej („Zbadaj element” w Chrome).

Chrome od razu wskazał nam selektor CSS za pomocą którego możemy się dostać do elementu, więc skorzystajmy z niego 😉
next_button = driver.find_element_by_css_selector('a.next.page-numbers')Mamy teraz dostęp do przycisku (a konkretnie linku będącego znacznikie <a>), więc możemy po prostu w niego kliknąć.
next_button.click()I prawdopodobnie w tym momencie zobaczysz błąd.
selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted: Element … is not clickable at point (190, 651). Other element would receive the click
I to jest właśnie jedna z trudności używania Selenium.
Skąd ten błąd? Sprawdźmy jak wygląda strona po wystąpieniu powyższego błędu

Na dole strony widzimy komunikat o plikach cookies, który z punktu widzenia przeglądarki zasłania przycisk „Next”. Co prawda gdy przewiniemy stronę jeszcze trochę w dół przycisk nie jest niczym zasłonięty, jednak Selenium samo w sobie nie jest w stanie tego zauważyć.
Zamknijmy więc najpierw komunikat o plikach cookies.
Skorzystajmy z możliwości wyszukania linku za pomocą jego tekstu.
cookies_accept_button = driver.find_element_by_link_text('Rozumiem')
cookies_accept_button.click()Komunikat został zamknięty. Spróbujmy ponownie odwiedzić następną stronę.
next_button.click()
print(driver.current_url)
# https://kamil.kwapisz.pl/page/2/Po wypisanym adresie URL widać, że nasza przeglądarka przeszła do następnej strony.
To jest metoda, którą w scrapowaniu przy użyciu Selenium bardzo Wam zalecam. Największą zaletą tego narzędzia jako środowiska do scrapowania jest możliwość jak najlepszego odwzorowania zachowania użytkownika, dlatego warto to wykorzystać i zachowywać się dokładnie jak użytkownik, który posługuje się właśnie tymi przyciskami.
Ponadto nie musimy się wtedy martwić o to czy następna strona wyników nie będzie pusta.
Zachowanie linków paginacji
Trzecia metoda polega na pobraniu nastepnego w kolejności adresu URL korzystając ze znalazienego przycisku „Next”.
next_url = next_button.get_attribute('href')Możemy teraz po prostu wejść na pobrany adres za pomocą metody get.
W przypadku tej metody również nie musimy martwić się czy następna strona posiada wyniki.
Mimo wszystko zalecam skorzystać z drugiej metody, czyli po prostu kliknąć w przycisk 🙂
Kiedy trzecia metoda może się przydać?
Nie zawsze chcemy aby nasz scraper wchodził od razu na kolejną stronę. Czasami lepiej najpierw pobrać linki, a dopiero później po nich przechodzić. I właśnie do tego przydatna będzie trzecia metoda.
Jest to jednak rzadki scenariusz w Selenium.
Podsumowanie
Tak naprawdę masz już wszystko, co jest potrzebne do scrapowania w Selenium.
Selenium nie jest narzędziem przeznaczonym do scrapowania, jednak zdecydowanie się scrapować przy jego pomocy 🙂
Chciałbym jednak tutaj wtrącić dygresję dotyczącą przyszłości web scrapingu.
Narzędzia blokujące web scraping stają się coraz skuteczniejsze. Póki co świetnym obejściem tej blokady są proxy, jednak jest to dość kosztowne rozwiązanie.
Innym problemem są captche, które uruchamiają się w momencie wykrycia zachowania, które odbiega od normalnego użytkowania strony przez człowieka.
Niezbędne stają się narzędzia wykorzystujące przeglądarki, które pozwalają wykonać kod JavaScript oraz wyświetlić obrazki.
Wydaje mi się, że ich waga będzie stale rosnąć, zmuszając scraperów do zrezygnowania z szybkości scrapingu na korzyść zachowania pozorów i udawania prawdziwego użytkownika strony.
Wtedy umiejętność „web scraping Selenium” może okazać się bardzo potrzebna 🙂
Co prawda istnieją również konkurencyjne i lżejsze rozwiązania takie jak puppeteer i splash, jednak Selenium jest stale jednym z popularniejszych wyborów 🙂
Jeśli chcesz być na bieżąco z najnowszymi materiałami, polub nasz fanpage na Facebooku:
https://www.facebook.com/kamil.kwapisz.python
Dodatkowe źródła
- https://selenium-python.readthedocs.io/
- https://medium.com/dreamcatcher-its-blog/5-simple-tips-for-improving-automated-web-testing-or-efficient-web-crawling-using-selenium-python-43038d7b7916
- https://www.w3schools.com/cssref/css_selectors.asp
Dzięki za dotrwanie do końca!
Jeżeli masz jeszcze jakieś pytania dotyczące web scrapingu w Selenium, czy też ogólnie web scrapingu czy automatyzacji to pisz śmiało!
Pozdrawiam serdecznie!
Kamil Kwapisz


