


Każdego dnia internet przemierzany jest przez tysiące botów, głównie firmy Google. Jak działają takie boty? W jaki sposób widzą strony internetowe i jak się po nich poruszają? Jak dużo jest botów w internecie?
Czym jest bot?
Bot to program komputerowy, który w sposób zautomatyzowany wykonuje pewne zadania w internecie.
Głównym powodem tworzenia botów jest automatyzacja procesów i polepszenie ich skalowalności. Praca, która wykonana manualnie zajmie godzinę, wykonana przez boty może zająć 5 minut.
Jak działają boty Google?
Web crawlery stworzone przez Google nazywane Googlebot wykonują proces zwany crawlowaniem. Jest to czynność polegająca na odkrywaniu nowych stron, bądź aktualizowaniu stron już znanych wyszukiwarce. O crawlowaniu pisałem już tutaj.
W rzeczywistości nazwa Googlebot odwołuje się do kilku rodzajów botów:
- Googlebot Desktop – symuluje użytkownika z komputera,
- Googlebot Smartphone – symuluje użytkownika z urządzeń mobilnych,
- Googlebot Video – bot przeznaczony wyłącznie do materiałów filmowych,
- Googlebot Images – bot przeznaczony do zdjęć, indeksujący zdjęcia w Google Grafika,
- Googlebot News – bot przeznaczony do newsów.
Bota Google możemy rozpoznać po nagłówku HTTP user-agent oraz adresie IP.
Googlebot na początku każdego procesu crawlowania tworzy listę linków, które ma odwiedzić.
Jak Google znajduje strony?
Wyszukiwarki posiadają wiele sposób na odnajdowanie linków. Najważniejszym jest znajdowanie linków do strony na innych, wcześniej zaindeksowanych stronach. Jak pisałem w poprzednim artykule o SEO linki prowadzące do naszej strony z zewnątrz (tzw. linki przychodzące) są najważniejszym czynnikiem rankingowym.
Mapy witryny
Innym popularnym sposobem jest przeszukiwanie map strony (ang. sitemaps). Mapy te są spisem adresów URL na stronie, które mają być dostępne z poziomu wyszukiwarek. Mapa witryny pokazuje również botom wyszukiwarki w jaki sposób crawlować stronę.



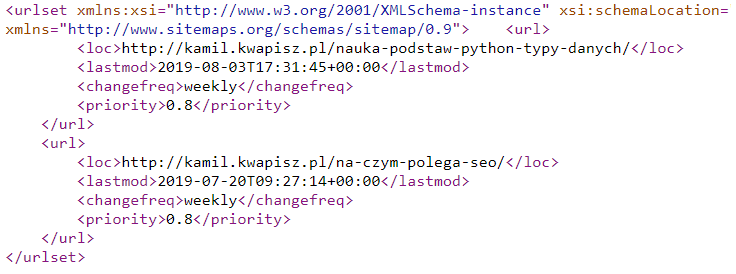
Sitemapy przechowują informacje o danym linku istotne z punktu widzenia wyszukiwarek takie jak data ostatniej modyfikacji, częstotliwość zmian czy ważność linku. Mapa strony powinna znajdować się w katalogu głównym, zazwyczaj jest to adres: http://kamil.kwapisz.pl/sitemap.xml
Jakich stron boty nie crawlują?
Domyślnie boty Google starają się odwiedzić każdą napotkaną stronę w internecie. Jeżeli jednak nie chcemy, aby dana strona była odwiedzana lub wolimy pozostawić ją niezaindeksowaną musimy sami poinstruować boty Google których stron nie powinny otwierać i indeksować.
robots.txt
Jednym ze sposobu blokowania ruchu botów na stronie jest stworzenie pliku robots.txt. Plik ten zawiera reguły blokujące lub zezwalające na dostęp określonego robota do danej strony.
Plik ten powinien znajdować się w katalogu głównym, podobnie jak mapa witryny.
Przykład zawartości pliku robots.txt:
# Grupa 1
User-agent: Googlebot
Disallow: /nogooglebot/
# Grupa 2
User-agent: *
Allow: /
Sitemap: http://www.example.com/mapawitryny.xmlMetatagi robots
Za pomocą metatagów umieszczonych w sekcji head strony internetowej możemy kontrolować zachowania robotów.
<head>(...)
<meta name="robots" content="nofollow">
<meta name="googlebot" content="noindex">(...)
</head>
Dzięki tagom możemy botom wydać następujące dyrektywy:
- noindex – nie indeksuj strony w wynikach wyszukiwań
- nofollow – nie otwieraj linków znajdujących się na tej stronie
- none – połączenie obu powyższych
- notranslate – nie proponuj tłumaczeń strony
- noimageindex – nie indeksuj obrazów znajdujących się na tej stronie
- nosnippet – nie pokazuj w wynikach fragmentu tekstu strony
- unavailable_after:– nie pokazuj strony w wynikach wyszukań po określonej dacie
Jeżeli chcemy botom wydać dyrektywę nieodwiedzania do konkretnego linku możemy to zrobić w następujący sposób: <a href="http://www.example.com" rel="nofollow">link</a>
Googleboty nie odwiedzają również stron, które uznały za zduplikowane treści, dlatego też warto ich unikać na swoich stronach 😉
Boty są wśród nas
Według raportu przeprowadzonego w 2016 roku aż 51.8% użytkowników internetu stanowią boty, z czego większość to boty określane jako „złe”, które nie są pożądane na naszych witrynach.
Jakie boty chodzą po naszych stronach?
Dobre boty
Wśród dobrych botów możemy znaleźć przede wszystkim boty wyszukiwarek internetowych (Google, Yahoo, DuckDuckGo, Bing). Aktywność tych botów jest istotna, gdyż dzięki nim nasza strona może zostać umieszczana w wynikach wyszukiwarek.
Kolejnym rodzajem „dobrych” botów są tzw feed fetchers. Są to boty, które dostarczają zawartość strony do aplikacji mobilnych i webowych. Wśród njapopularniejszych programów tego typu znajdziemy boty aplikacji mobilnej Facebooka, Androida czy Apple.
Po naszych stronach bardzo często chodzą również crawlery różnych firm zajmujących analizą stron. Mogą to być boty badające między innymi linki zewnętrzne, słowa kluczowe, czy też linkowanie wewnętrzne strony. Przykładami firm tak badających strony mogą być uncrawled.com, ahrefs, SEMrush czy Brand24.
Złe boty
Prawie 25 % ruchu w internecie stanowią boty podszywające się pod normalnych użytkowników. Boty te starają się upodobnić do użytkowników przeglądarek za pomocą zmiany nagłówka user-agent, sposobu przechowywania plików cookies czy nawet obsługi kodu JavaScript.
Głównym celem botów tego typu są ataki DDoS, których zadaniem jest doprowadzenie do przeciążenia serwera.
Innymi niechcianymi botami na naszej stronie są narzędzia hackerskie. Bardzo często hackerzy tworzą boty szukające słabych punktów na stronach internetowych, które mogą być furtką do przeprowadzenia ataku.
Jednym z najbardziej znienawidzonych botów są spamery. Są to programy stworzone w celu rozpowszechniania niechcianych i nachalnych treści reklamowych. Boty przechodzą po forach, blogach i portalach pozostawiając treść z reklamą.

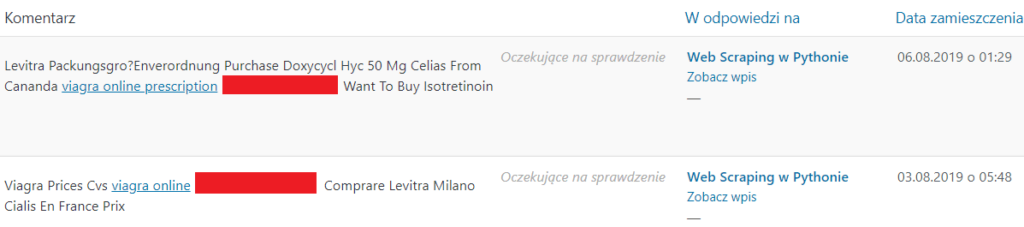
Za niechciane boty często uważane są również scrapery. Są to programy masowo pobierające treści ze strony internetowej.
Jeśli chcesz być na bieżąco z najnowszymi materiałami, polub nasz fanpage na Facebooku:
https://www.facebook.com/kamil.kwapisz.python
Źródła i dodatkowe materiały
- https://support.google.com/webmasters/answer/70897?hl=en
- https://support.google.com/webmasters/answer/182072
- https://yoast.com/what-is-googlebot/
- https://support.google.com/webmasters/answer/6062596?hl=pl
- https://developers.google.com/search/reference/robots_meta_tag?hl=pl
- https://www.imperva.com/blog/bot-traffic-report-2016/
- https://support.google.com/webmasters/answer/6062596?hl=pl