
Protokół HTTP to aktualnie podstawa większości aplikacji. Korzystasz z niego codziennie, nie tylko programując, lecz także (a może nawet przede wszystkim) wchodząc na strony internetowe i korzystając z aplikacji mobilnych. Nagłówek User-agent jest używany podczas każdej interakcji w ramach protokołu.
Mam nadzieję, że wystarczająco przekonałem Cię do zgłębienia tematyki prokołu HTTP. Dzisiaj opowiem Ci trochę o user-agentach, czyli „podpisie”, którego często nieświadomie używamy korzystając z internetu.
Nic, co robimy w internecie, nie jest w pełni anonimowe. Nawet korzystając z protokołu HTTP na stronach internetowych niewymagających logowania, pozostawiamy całkiem wyraźny ślad naszej aktywności.
Czy zastanawiałeś się kiedyś, jak wejście na stronę wygląda z punktu widzenia administratora?
66.249.65.159 - - [06/Nov/2014:19:10:38 +0600] "GET /news/ HTTP/1.1" 404 177 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.65.3 - - [06/Nov/2014:19:11:24 +0600] "GET /?q=%E0%A6%AB%E0%A6%BE%E0%A7%9F%E0%A6%BE%E0%A6%B0 HTTP/1.1" 200 4223 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.65.62 - - [06/Nov/2014:19:12:14 +0600] "GET /?q=%E0%A6%A6%E0%A7%8B%E0%A7%9F%E0%A6%BE HTTP/1.1" 200 4356 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"Analizując powyższy fragment logów (serwera nginx), możemy zobaczyć, że nasza aktywność zostawia ślad w postaci m.in. adresu IP, dokładnego czasu wejścia, użytego protokołu, kodu odpowiedzi, adresu pobieranego zasobu. Oprócz tego widoczny jest jeszcze string nazywany **User-agentem**: „Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
User-agent to jeden z nagłówków protokołu HTTP wykorzystywanego w każdym żądaniu. Wskazuje on na typ urządzenia, z jakiego został wykonany request. Dzięki niemu można sprawdzić, z jakiego systemu operacyjnego korzystał użytkownik oraz jakiej użył przeglądarki.
Wykorzystanie nagłówka user-agent w Web Scrapingu
Dlaczego powinniśmy myśleć o user-agentach, jeżeli chodzi o web scraping?
Sprawdźmy jak wygląda zwykły request w Pythonie wykonany bez zmian żadnych nagłówków.
import requests
resp = requests.get("http://httpbin.org/get")
print(resp.text)
>>> {
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.26.0",
},
"origin": "159.32.52.12",
"url": "http://httpbin.org/get"
}
Zwróć szczególną uwagę na nagłówek User-agent. Jeżeli chcemy zabezpieczyć naszą stronę przed próbami scrapowania danych bez problemu możemy usunąć requesty posiadające tego typu wartość nagłówka mając pewność, że są to boty.
Nagłówek możemy jednak bez problemu podmienić:
import requests
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " \
"AppleWebKit/537.36 (KHTML, like Gecko) " \
"Chrome/106.0.0.0 Safari/537.36"
resp = requests.get(
"http://httpbin.org/get",
headers={"User-agent": user_agent}
)
print(resp.text)
>>> {
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
},
"origin": "159.32.52.12",
"url": "http://httpbin.org/get"
}
Zastosowanie takiego nagłówka utrudni rozróżnienie ruchu botów od zwykłych użytkowników (jednak nadal jest to możliwe w stosunkowo prosty sposób, o czym dowiesz się w jednym z następnych maili).
Skąd pobrać user-agenta?
Możesz znaleźć go w narzędziach deweloperskich swojej przeglądarki. W Chrome wystarczy uruchomić narzędzia deweloperskie (ctrl + shift + I), następnie przejść do zakładki Network i odświeżyć stronę.
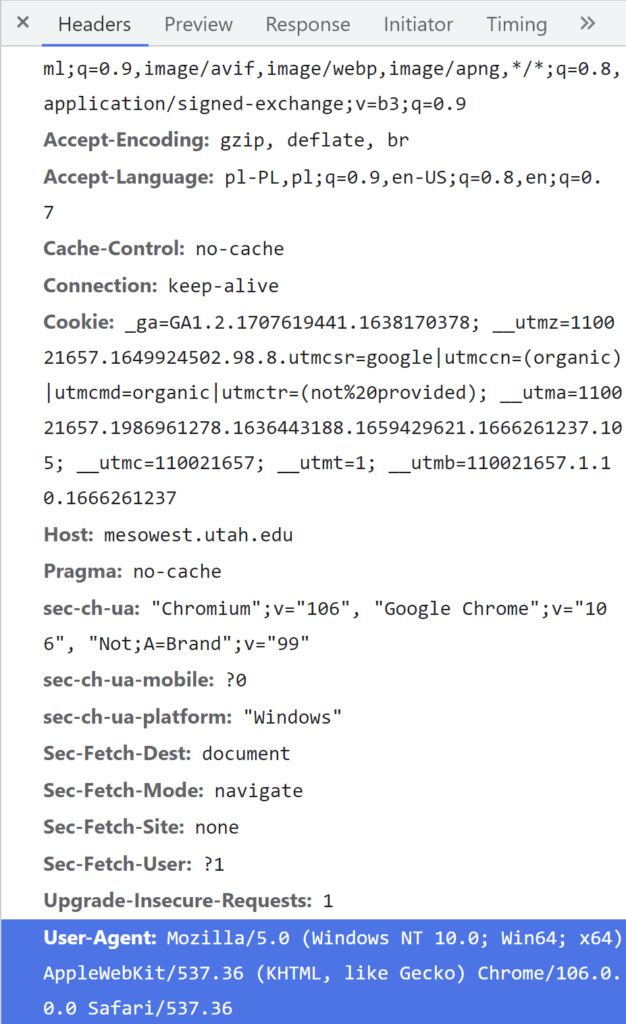
Innym sposobem jest skorzystanie z bazy gotowych user-agentów zdefiniowanych dla różnych przeglądarek.
W Pythonie możesz do tego celu użyć biblioteki user_agent.
>>> from user_agent import generate_user_agent
>>> ua = generate_user_agent(os=('linux',))
>>> ua
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2659.19 Safari/537.36'Używanie różnych user-agentów reprezentujących realne i często używane przeglądarki znacząco zmniejsza szanse na otrzymanie bana podczas web scrapingu. Warto również rotować wartościami nagłówków przy jednoczesnej rotacji proxy.
Jeżeli chcesz dowiedzieć się więcej o scrapingu koniecznie przeczytaj inne wpisy z kategorii Web scraping:


