
Jednym z powodów, dla których uwielbiam programowanie jest możliwość automatyzacji. W tym artykule pokażę Ci jak łatwo zautomatyzować przeglądarkę i czynności związane z internetem za pomocą Selenium. Dowiesz się również jak fajna może być automatyzacja Selenium 🙂
Mówi się, że programista to osoba, która spedzi 20 godzin aby zautomatyzować zadanie, które da się wykonać w 10 godzin. Czasami aż trudno się z tym nie zgodzić.
Automatyzacją nazywamy proces zastąpienia ludzkiej pracy na pracę maszyn, robotów czy botów.
W dzisiejszym świecie umiejętność automatyzacji może być nazywaną „kompetencją przyszłości”. Najważniejszą i najcenniejszą walutą jest czas, a dzięki automatyzacji możemy go trochę odzyskać.
Co możemy automatyzować?
Dzięki aktualnemu poziomowi rozwoju technologicznego automatyzować możemy praktycznie wszystko.
Od wysyłki maili, przez proces księgowania płatności aż do automatyzacji procesu badania rynku czy nawet przeprowadzania rozmów z klientem (np. za pomocą chatbota).
Jak automatyzować?
Automatyzację powinniśmy zacząć od czegoś co w programowaniu nazywamy profilowaniem – czyli analizą procesów, jakie wykonujemy. Kiedy zastanowimy się jakie procesy (powtarzalne czynności) podczas tygodnia zajmują nam najwięcej czasu, będziemy wiedzieć co w pierwszej kolejności powinniśmy zautomatyzować.
Automatyzacja w internecie
Internet jest wręcz nastawiony na automatyzację, jest on wypełniony przez boty.
Selenium + Python
Czym jest Selenium? Selenium, a konkretnie Selenium WebDriver to narzędzie do automatyzacji zadań za pomocą przeglądarki internetowej.
Prościej mówiąc: polega to na tym, że pisząc kod mówimy co nasza przeglądarka ma zrobić bez naszej dalszej pomocy. Możemy zaprogramować przeglądarkę tak, aby weszła na konkretną stronę internetową, wypełniła formularz i kliknęła w przycisk „Wyślij”.
Aby Selenium działało potrzebny jest obiekt nazywany WebDriverem.
WebDrivery
WebDriver to praktycznie rzecz ujmując obiekt naszej przeglądarki internetowej. Selenium dostarcza nam drivery najpopularniejszych przeglądarek:
- Chrome
- Firefox
- IE
- Edge
- Opera
from selenium import webdriver
driver = webdriver.Chrome()Aby webdriver działał potrzebujemy pobrać na komputer driver dostarczony przez twórców przeglądarki. Powyższy kod zadziała tylko jeżeli nasz driver do Chrome znajduje się w zmiennej PATH.
W innym wypadku musimy podać go ręcznie:
driver = webdriver.Chrome(r'C:\path\to\driver')Zachęcam Cię jednak do skorzystania z biblioteki webdriver_manager, która za Ciebie pobierze odpowiedni driver.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())Teraz możemy wydać polecenie wejścia na stronę internetową:
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://kamil.kwapisz.pl/")W tym momencie otworzy się okno przeglądarki Chrome:

Po chwili przeglądarka sama wejdzie na podany adres URL:
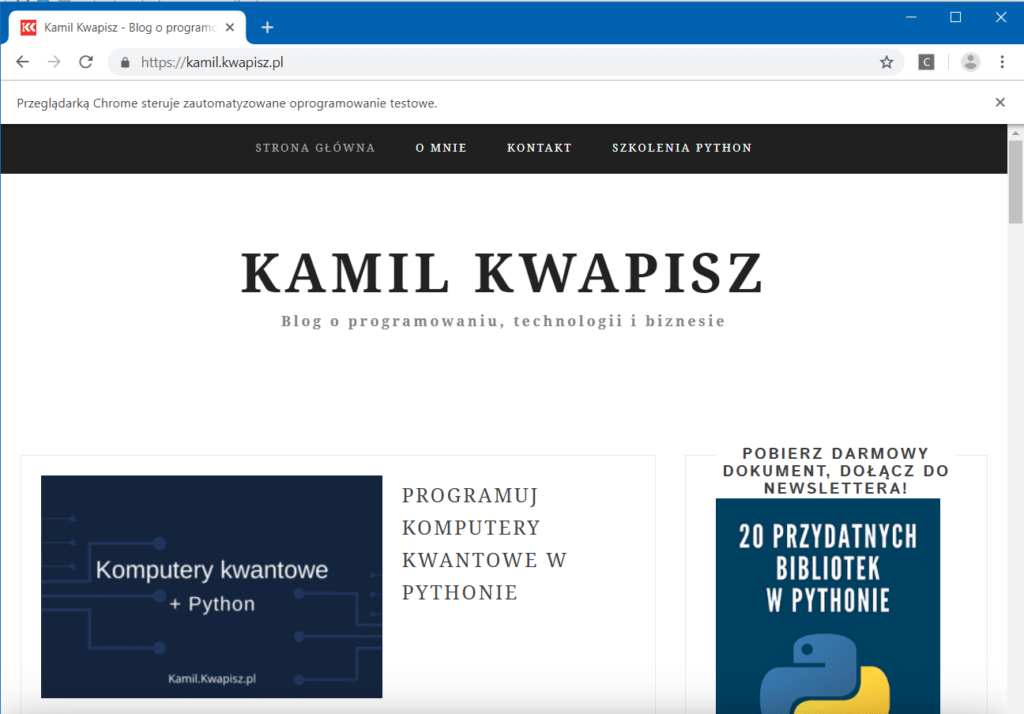
W tym momencie możemy już wchodzić w interakcję ze stroną.
Znajdowanie elementów
Aby wykonywać na stronie różne czynności musi najpierw zlokalizować jej konkretne elementy tak, aby driver mógł z nich korzystać.
Elementy możemy szukać za pomocą:
- ID
- nazwy
- XPath
- nazwy znacznika
- selektorze CSS
- tekście linka
Spróbujmy wyszukać pole wyszukiwarki na blogu. Przydatnym będą tutaj narzędzia deweloperskie Chrome, tzw „zbadaj element” dostępny w kontektowym menu (pod prawym przyciskiem myszy).
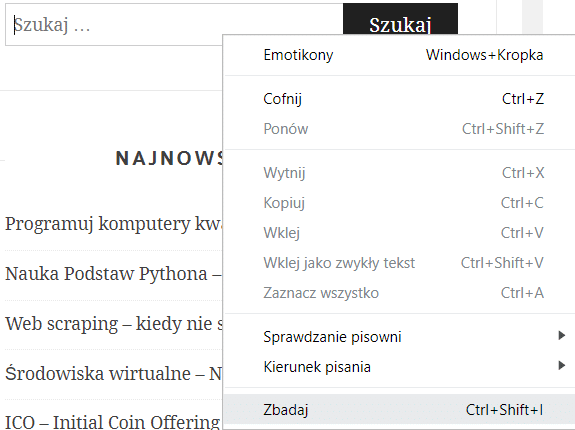
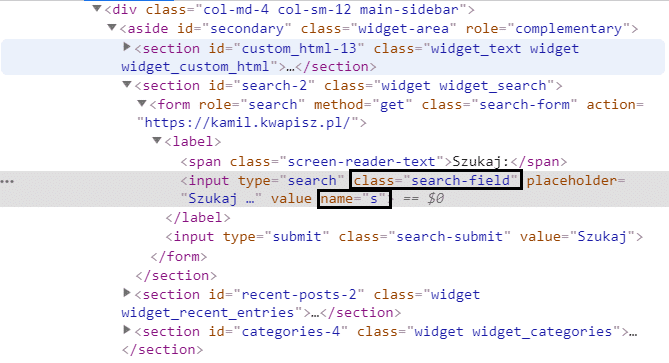
W tym momencie możemy skorzystać z wyszukiwania po klasie lub po nazwie.
search_input = driver.find_element_by_name('s')
print(search_input.tag_name) # 'input'
print(search_input.get_attribute('placeholder')) # 'Szukaj …'To samo możemy zrobić szukając po nazwie klasy:
search_input = driver.find_element_by_class_name('search-field')
print(search_input.get_attribute('placeholder')) # 'Szukaj …'Przydatnym sposobem wyszukiwania jest również skorzystanie z XPath. Ścieżkę XPath do elementu możesz skopiować z narzędzi deweloperskich.
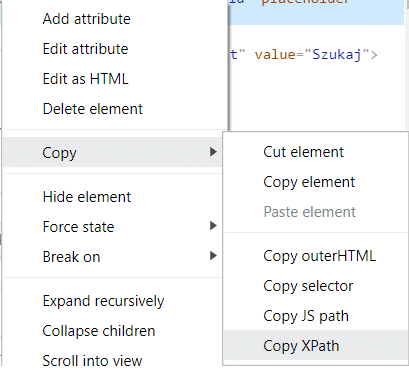
path = """//*[@id="search-2"]/form/label/input"""
search_input = driver.find_element_by_xpath(path)
print(search_input.get_attribute('placeholder')) # 'Szukaj …'Wpisywanie tekstu i wysyłanie formularza
Gdy mamy pobrany element, który jest polem formularza możemy do niego wpisać tekst. Służy do tego metoda send_keys:
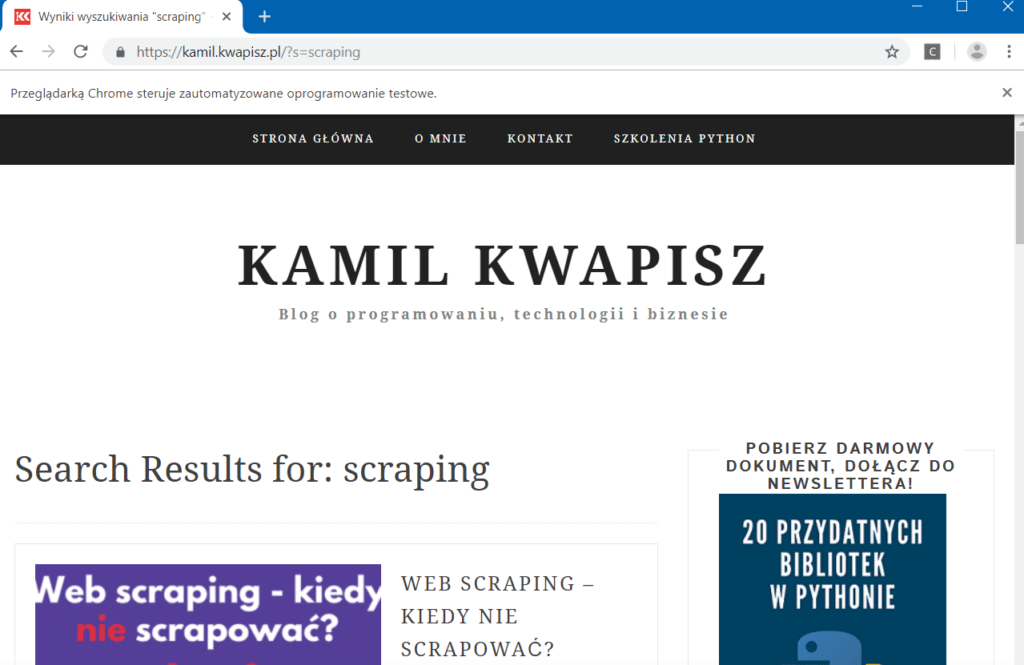
search_input.send_keys('scraping')
Spróbujmy teraz pobrać obiekt przycisku „Szukaj”:
search_btn = driver.find_element_by_class_name('search-submit')Teraz możemy po prostu kliknąć w przycisk.
search_btn.click()Możemy teraz zobaczyć, że formularz został wysłany, a przeglądarka pokazała nam wyniki wyszukania i artykuły o web scrapingu.
Opcje sterownika
Korzystając z Selenium nie musimy ograniczać się do fabrycznych ustawień przeglądarki. Możemy ją dodatkowo konfigurować korzystając z opcji. W przypadku Chrome posłużymy się następującymi opcjami:
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# uruchamiamy przeglądarkę w języku angielskim
chrome_options.add_argument('--lang=en')
# uruchamiamy przeglądarkę zmaksymalizowaną
chrome_options.add_argument('start-maximized')
# wyłączamy pasek informujący o tym, że przeglądarką steruje program
chrome_options.add_argument('disable-infobars')
# wyłączamy dodatki
chrome_options.add_argument("--disable-extensions")Teraz możemy przekazać obiekt opcji uruchamiając przeglądarkę.
driver = webdriver.Chrome(driver_path, chrome_options=chrome_options)Przeglądarka typu headless
Istnieje również możliwość uruchomienia przeglądarki w trybie headless. Oznacza to, że nie zostanie nam wyświetlone okno przeglądarki, a cały proces wykona się „w tle”.
Aby uruchomić tryb headless należy ustawić odpowiednią opcję:
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(driver_path, chrome_options=chrome_options)Wykorzystanie Selenium
Automatyzacja Selenium
Moim zdaniem automatyzacja to najlepsze zastosowanie Selenium. Swoboda jaką daje nam to narzędzie pozwala zautomatyzować praktycznie każdą powtarzalną czynność, którą wykonujemy w przeglądarce internetowej.
Możliwość logowania się do różnych portali, wykorzystanie rzeczywistej przeglądarki dają naprawdę ogromne możliwości.
Testy automatyczne
Jeżeli chodzi o komercyjne zastosowanie Selenium to królują tutaj testy automatyczne Quality Assurance (QA).
Stworzone aplikacje internetowe warto przetestować, sprawdzić czy każdy klikalny element prowadzi tam gdzie powinien, czy wszystko się wyświetla poprawnie, czy też czy w każdy guzik da się kliknąć.
W tym pomaga właśnie Selenium, które jest zdecydowanie najpopularniejszym wyborem do tego zadania.
Web scraping
Selenium „znalazło” swoją niszę również w web scrapingu.
Jednym ze sposobów blokowania scrapowania jest sprawdzenie czy użytkownik wykonał kod JavaScript zamieszczony na stronie, lub też dynamiczne generowanie treści.
W obu przypadkach pomocne okaże się Selenium. Scrapując w ten sposób zawsze otwierana jest prawdziwa przeglądarka (typu headless lub nie), która wykona kod JS.
Jeżeli jesteś zainteresowany artykułem na temat scrapowania z Selenium to daj znać 😉
Jeśli chcesz być na bieżąco z najnowszymi materiałami, polub nasz fanpage na Facebooku:
https://www.facebook.com/kamil.kwapisz.python



Cześć,
Dobra zachęta do używania Selenium – jest to kombajn ale zdecydowanie robi swoją robotę. Od siebie mogę dodać, że dla tych, którzy lubią mieć zawsze stabilne środowisko jest kontener Docker’a z Selenium HUB, który w zależności od dodanych kontenerów uruchamia nasze testy na Chrome, Firefox i innych. No i nie trzeba martwić się plikami ze sterownikami czy dostosowywaniem środowiska 🙂
W moim przypadku Selenium służył głównie do robienie screenów stron internetowych – a o scrapowaniu w Selenium chętnie bym poczytał 😉
Cześć!
Dzięki za informacje o kontenerze dockera z Selenium, na pewno przydatna sprawa 🙂
Świetnie, że jest zainteresowanie tematem scrapingu przy użyciu selenium, chętnie się zajmę takim wpisem 🙂
Pozdrawiam!
Bardzo fajny artykuł.
Również byłbym zainteresowany scrapowaniem z użyciem Selenium.
Dzięki! 😉
Artykuł o tym wrzucę niedługo 🙂
Mam pytanie jak zapisać plik w pythonie by każdy ( nie posiadający rozszerzenia) mógł go otworzyć i uruchomić.
Tutaj niestety sprawa nie zawsze jest prosta 🙂 Można przekształcić pythonowy plik do pliku .exe za pomocą bibliotek takich jak PyInstaller, cx_freeze czy py2exe. Nie mogę tutaj jednak nic polecić bo sam mam niewielkie doświadczenia z taką pracą 🙂
Świetny artykuł. bardzo obszerny i wszystko świetnie wyjaśnia nawet dla takiego laika jak ja 🙂 Dziękuję dodaje do zakładek
Dzięki! Cieszę się, że artykuł się przydaje 🙂
Bardzo dobrze wytłumaczone – dzięki za ten post 🙂
Dzięki za komentarz! Bardzo się cieszę, że wpis Ci się podoba 🙂
A jak kopiować i wklejać ze pomocą pythona ?
Operację kopiowania wykonuje się najpierw pobierając odpowiedni teksst do zmiennej, a następnie umieszczając w miejscu docelowym, np. za pomocą metody send_keys w Selenium, aby wypełnić pole tekstowe na stronie 🙂